
EN
DE

Cybersicherheit ist in der heutigen digitalen Welt wichtiger denn je. Mit den aktuell drastisch zunehmenden Angriffen auf Unternehmen und Organisationen wird die Notwendigkeit bewährter Sicherheitspraktiken immer offensichtlicher. Doch in einer zunehmend von künstlicher Intelligenz (KI) unterstützten Umgebung müssen wir nicht nur unsere Systeme und Daten schützen, sondern auch die KI-Modelle selbst.
Die Relevanz des Themas zeigt sich auch dadurch, dass die Sicherheit von KI-basierten Anwendungen eine Komponente der aktuellen technologischen Top-Trends von Gartner ist - AI TRiSM (KI-Vertrauens-, Risiko- und Sicherheitsmanagement). Dieses Framework beinhaltet Lösungen, Techniken und Prozesse zur Interpretierbarkeit und Erklärbarkeit von Modellen (siehe Blogartikel Explainable AI), zur Privatsphäre, zum Modellbetrieb und zur Abwehr von Angriffen für Kunden und Unternehmen. Darüber hinaus haben 23 Cybersicherheitsbehörden aus 18 Ländern einen Leitfaden zur Entwicklung sicherer KI-Modelle bereitgestellt.
In diesem Blogartikel werfen wir einen genaueren Blick auf die Sicherheit von KI-Modellen und präsentieren einen kurzen Überblick der gängigsten Angriffsvektoren. Erfahren Sie, wie sich Unternehmen und Organisationen gegen diese Bedrohungen wappnen können und welche Sicherheitsmaßnahmen unerlässlich sind, um die Integrität und Funktionalität von KI-Modellen zu gewährleisten.
Um die Sicherheit von KI-Modellen von der allgemeinen IT-Sicherheit abzugrenzen, ist es wichtig zu verstehen, dass die KI-Modelle oft als letzte Verteidigungslinie dienen, also unerwünschte oder schädliche Aktivitäten erkennen und verhindern müssen, selbst wenn andere Sicherheitsmaßnahmen versagen. Während die IT-Sicherheit sich auf die Sicherung von Netzwerken, Geräten und Anwendungen konzentriert, zielt die Sicherheit von KI-Modellen darauf ab, speziell die Integrität, Robustheit und Vorhersagequalität dieser Modelle sicherzustellen. Angriffe auf KI-Modelle können zu unterschiedlichen Zeitpunkten während ihres Lebenszyklus (siehe Blogartikel ML Lifecycle)stattfinden. Im Folgenden werden wir unterschiedliche Szenarien und mögliche Gegenmaßnahmen beleuchten.
Wenn die Angreifer Zugriff auf die Trainingsdaten während der Modellentwicklung bekommen, können sie durch gezielte Anpassungen dieser Daten die Performance des Modells verschlechtern. Dies kann beispielsweise durch das Hinzufügen falscher Daten, der Anpassung bestehender Daten oder die Änderung der Labels in den Daten geschehen. Darüber hinaus kann durch gezielteres Anpassen der Trainingsdaten mit sog. Triggern die Entscheidung des Modells zu Gunsten der Angreifer beeinflusst werden, das Modell also eine Backdoor enthalten. Bei Bildern können dies z.B. Muster sein wie Abb. 1 zeigt. Das Muster wird in Trainingsbeispielen platziert, die alle das gleiche Label erhalten. So assoziiert das Modell die entsprechende Klasse mit dem Trigger und die Entscheidung des deployten Modells kann durch den Trigger gezielt beeinflusst werden.
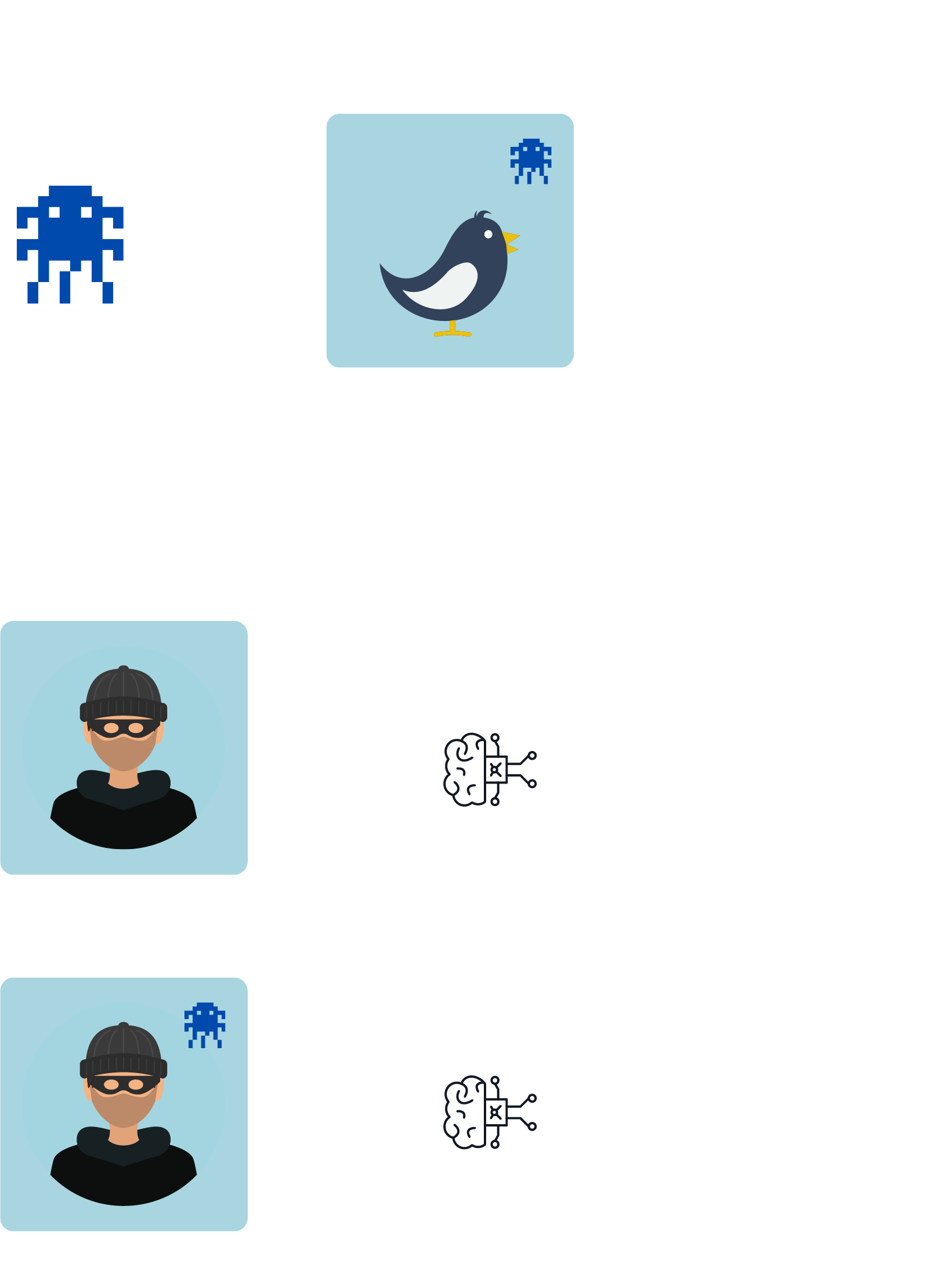
Eine erfolgreiche Attacke zeichnet sich dadurch aus, dass sich das Modell bei Anfragen ohne den spezifischen Trigger normal verhält, bei Anfragen, die den Trigger enthalten, jedoch das von den Angreifern gewünschte Label vorhersagt. Dadurch sind Modelle mit Backdoor schwer zu identifizieren, wenn man nur die üblichen Performance-Metriken betrachtet. Insbesondere wenn bereits vortrainierte Modelle als Basis der eigenen Entwicklung dienen, können potenziell enthaltene Hintertüren auf das eigene Modell übertragen werden.
Daher sollten vortrainierte Modelle nur aus vertrauenswürdiger Quelle genutzt werden (Supply Chain Security). Die eigenen Trainingsdaten sollten je nach Kritikalität des Anwendungsfalles durch strenge Zugriffsbeschränkungen, kryptographische Verfahren und Hashing vor unerwünschten Modifikationen geschützt werden.
Sogenannte Evasion Attacks zielen auf bereits deployte und operationalisierte Modelle ab. Angreifende versuchen durch menschlich kaum wahrnehmbare Modifikationen der Eingangsdaten eine Fehlklassifikation des Modells zu verursachen. Wie Abbildung 2 ersichtlich, reicht im Falle von Bilderkennungsmodellen teilweise schon die Manipulation einiger weniger Pixel um eine drastisch andere Modellantwort zu erhalten.
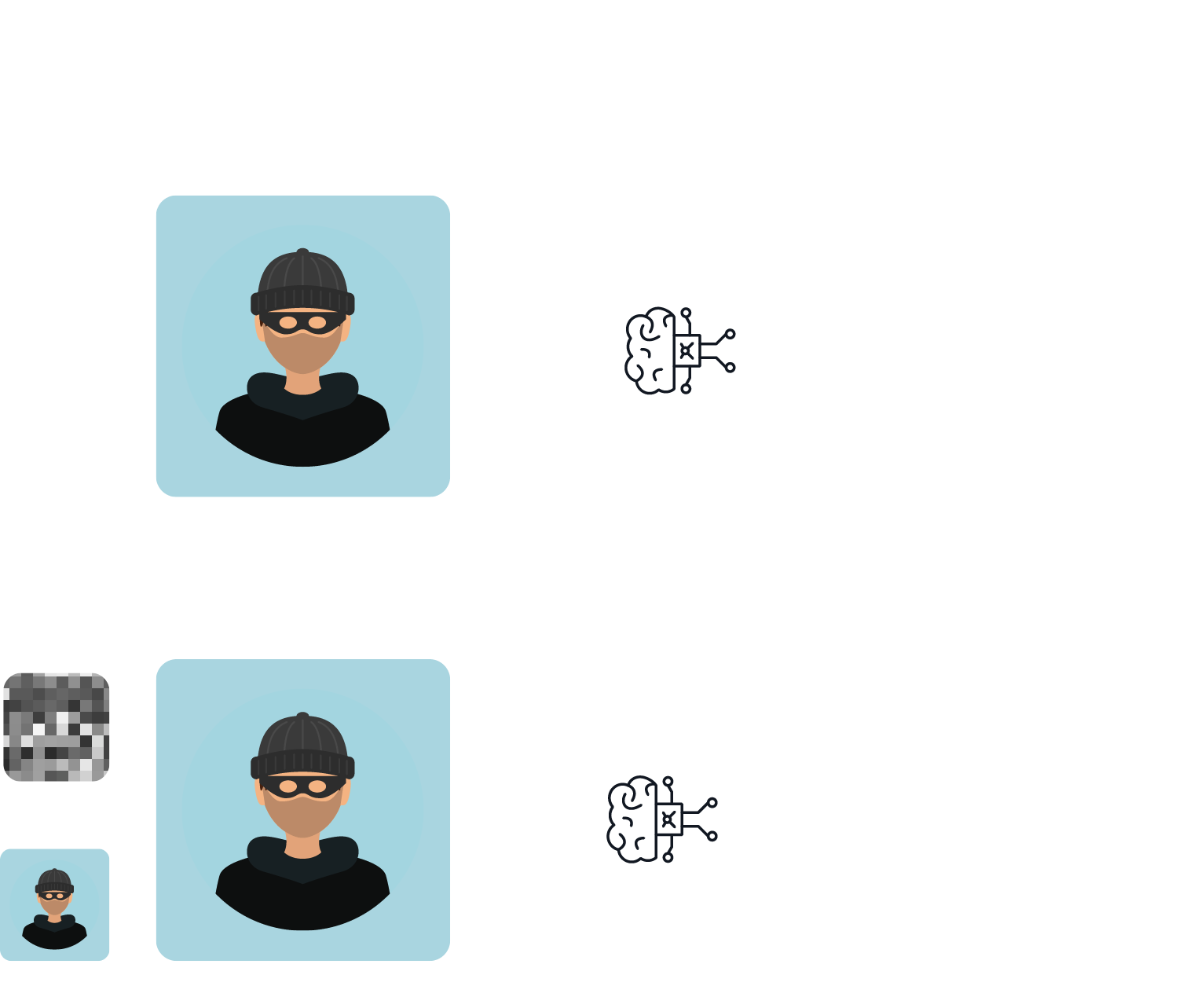
Diese Angriffe können in gezielte Angriffe unterteilt werden, bei denen der Angreifer das Modell zwingt, den gewünschten Zielwert vorherzusagen, und in ungerichtete Angriffe, die eine allgemeine Verringerung der Modellgenauigkeit oder der Vorhersagevertrauenswürdigkeit bewirken. Evasionsangriffe können in der physischen oder digitalen Welt stattfinden. So hat in der Vergangenheit das gezielte Bekleben von Verkehrschildern mit einzelnen Stickern zu Missklassifikationen durch autonome Fahrzeuge geführt. In einer ähnlichen Weise kann die Modellanfrage digital, wie in unserem Beispiel manipuliert werden. Dies betrifft auch sog. Large Language Models, wie z.B. ChatGPT. Diese Modelle sind durch exzessives Fine-tuning darauf optimiert, keine toxischen Inhalte wie z.B. die Erstellung von personalisierten Phishing-Mails, zu erzeugen. Diese Safeguards konnten jedoch durch gezieltes Hinzufügen von Textbausteinen an die Modellanfrage umgangen werden(https://llm-attacks.org/).
Auch hier gilt – wenn ein vortrainiertes Modell als Basis für die eigene Modellentwicklung genutzt wird, können sich dessen Schwachstellen auf das eigene Modell übertragen.
Die Identifikation von den oben diskutierten leicht manipulierten Modellanfragen ist schwierig, da die Änderungen oft sehr subtil sind. Jedoch können Modelle durch Antizipation solcher Attacken, also durch Aufnahme von leicht veränderten Beispielen in die Trainingsdaten, robuster gemacht werden.
Auch bei Attacken zur Informationsextraktion zielen Angreifer auf bereits deployte und operationalisierte Modelle ab, um entweder das ganze Modell oder Teile der Trainingsdaten zu extrahieren. Die Angreifer können dabei gezielt nach vertraulichen Informationen wie persönlichen Identifikationsdaten, Unternehmensgeheimnissen oder anderen sensiblen Daten suchen. Im Extremfall kann eine ausreichende Menge von Daten aus dem Modell extrahiert werden, um eine vollständige Rekonstruktion des Modells zu ermöglichen.
Eine gängige Methode zur Durchführung dieser Angriffe besteht darin, viele sorgfältig erstellte Eingaben zu verwenden, um Stück für Stück die Funktionsweise des Modells zu explorieren. Darüber hinaus können Angreifer auch versuchen herauszufinden, ob ein bestimmtes Datenbeispiel als Teil der Trainingsdaten eines Modells verwendet wurde. Das ist aus Datenschutzgründen problematisch, da dadurch individuelle, potenziell sensible Datenattribute rekonstruiert werden können, wie z.B. medizinische Aufzeichnungen oder personenbezogene Informationen.
Diese Art von Angriffen wird erleichtert, wenn öffentlich zugängliche vortrainierte Modelle als Basis der eigenen Modellentwicklung genutzt werden, da hier viele Details über die Funktionsweise des Modells (z.B. dessen Architektur) bekannt sind. Mögliche Schutzmaßnahmen sind eine starke Einschränkung des Modelloutputs, also nur wirklich notwendige Informationen aus der Modellantwort über die API zugängig zu machen. Der Datensatz für das Modelltraining sollte soweit möglich von nicht notwendigen sensiblen Informationen bereinigt sein. Darüber hinaus sollte sichergestellt werden, dass das Modell gut generalisiert und nicht auf die Trainingsdaten overfittet, diese also quasi auswendig lernt.
Zusammenfassend gibt es für die verschiedenen Angriffsszenarien eine Reihe von möglichen Verteidigungsmechanismen, die als feste Schritte in der Modellentwicklung berücksichtigt werden müssen:
ls Fazit unseres Artikels möchten wir Sie ermutigen, aktiv zu werden und die Sicherheit Ihrer eigenen KI-Modelle zu bewerten, insbesondere auch in Hinblick darauf, dass solche Schritte in einer nahen Zukunft werden (siehe Blogartikel AI-Act).
https://www.ncsc.gov.uk/files/Guidelines-for-secure-AI-system-development.pdf
https://www.bsi.bund.de/SharedDocs/Downloads/EN/BSI/KI/Practical_Al-Security_Guide_2023.html
https://english.aivd.nl/publications/publications/2023/02/15/ai-systems-develop-them-securely
https://www.gartner.com/en/articles/what-it-takes-to-make-ai-safe-and-effective
