
EN
DE

In diesem Blogartikel möchten wir einen kurzen Einblick in die Welt von EdgeAI bieten.
Im Gegensatz zu herkömmlichen Methoden, bei denen die Datenverarbeitung hauptsächlich in der Cloud stattfindet, ermöglicht EdgeAI die Verarbeitung der Daten direkt dort, wo sie erzeugt werden. Der Begriff “Edge” bezieht sich auf Geräte am Rande eines Netzwerks, die in der Lage sind, die Daten zu verarbeiten. Diese Technologie bietet einige Vorteile, stellt uns jedoch auch vor Herausforderungen. Wir richten unseren Fokus auf eine spezifische Herausforderung - die begrenzte Rechenleistung und Speicherkapazität von Edge-Geräten. Als Lösungsansätze präsentieren wir Pruning und Quantisierung, die eine signifikante Reduzierung der Modellgröße und eine Beschleunigung der Inferenz ermöglichen, ohne dabei die Genauigkeit des Modells erheblich zu beeinträchtigen.
“EdgeAI”, bezeichnet die Verlagerung der Datenverarbeitung mit KI an den Rand des Netzwerks, nämlich dorthin, wo die Daten entstehen. In einer Ära der digitalen Transformation gewinnt die Integration von KI in eine Vielzahl von Geräten - von industriellen Maschinen bis hin zu vernetzten Produktionsanlagen – im Kontext von Industrie 4.0 zunehmend an Bedeutung. Diese Entwicklung ist entscheidend, da sie Unternehmen dabei unterstützt, ihre Produktionsabläufe zu optimieren und die Effizienz zu steigern. Durch die Implementierung und Nutzung von EdgeAI können Unternehmen ihre Produktionsprozesse in Echtzeit überwachen, anpassen und innovative Lösungen entwickeln, um die spezifischen Herausforderungen der modernen Industrie zu bewältigen. Diese Herausforderungen können vielfältig sein, von der Verbesserung der Produktqualität bis hin zur Reduzierung von Ausfallzeiten. Das könnte durch eine automatische Qualitätssicherung oder einer frühzeitigen Wartung der Maschinen, anhand der gesammelten und ausgewerteten Daten erfolgen.
Laut einem Bericht von Fortune Business Insights [1] wird erwartet, dass der weltweite Markt für diese aufstrebende Technologie von circa 20 Milliarden USD im Jahr 2023 auf ungefähr 110 Milliarden USD im Jahr 2029 ansteigen wird und das Potenzial hat, unsere Nutzung von KI grundlegend zu verändern.
Durch die direkte Datenverarbeitung “at the Edge” ergeben sich verschiedene Vorteile, wie beispielsweise:<br>
Aber wie bei jeder neuen Technologie gibt, es auch hier einige Herausforderungen zu bewältigen.
Die Integration von leistungsstarken KI-Modellen auf Edge-Geräten wird durch die begrenzte Rechenleistung und Speicherkapazität dieser Geräte vor Herausforderungen gestellt. Insbesondere die wachsende Komplexität moderner Modelle wie das GPT-3 mit seinen 175 Milliarden Parameter und einem Speicherbedarf von etwa 350 Gigabyte verdeutlichen diese Problematik. Die steigende Komplexität der Modelle führt zu einer Zunahme der Parameteranzahl, was die Anpassung an die beschränkten Ressourcen von Edge-Geräten erschwert. Es ist wichtig zu beachten, dass diese Herausforderungen nicht nur für hochkomplexe Modelle wie GPT-3 gilt, sondern auch für einfachere Modelle. Selbst Modelle mit einer geringeren Anzahl an Parameter können aufgrund der begrenzten Rechenleistung und Speicherkapazität von Edge-Geräten problematisch sein.
Die Vernetzung von Edge-Geräten stellt eine weitere Schwierigkeit dar, meistens wenn diese über einen eingeschränkten oder unzuverlässigen Internetzugang verfügen. Das erschwert den effizienten Transport von Modellen oder größeren Datenmengen zwischen den Endgeräten und der zentralen Infrastruktur. In kommenden Blogartikel wollen wir diese Herausforderungen genauer betrachten.
Trotz der gesteigerten Sicherheit durch EdgeAI ist es wichtig zu berücksichtigen, dass sensible Daten direkt auf den Geräten gesammelt und verarbeitet werden. Dies birgt potenzielle Sicherheitsrisiken und könnten Angreifern eine Angriffsfläche bieten. Daher ist es entscheidend, die Sicherheit und Vertraulichkeit der Daten zu gewährleisten.
In diesem Blogartikel möchten wir uns intensiv mit der Herausforderung der limitierten Ressourcen auseinandersetzen und folgende Fragen klären: Wie können wir unsere KI-Modelle so optimieren, dass sie ohne Einschränkungen auf den begrenzten Speicher- und Rechenkapazitäten von Edge-Geräten effizient arbeiten? Wie lässt sich die Inferenzgeschwindigkeit verbessern, um Anwendungen wie eine Echtzeit-Videoanalyse oder die automatisierte Anomalieerkennung bei Industriegeräten optimal zu unterstützen?
Das Ziel dieses Beitrags ist es diese Fragen zu beantworten, indem wir einen potenziellen Anwendungsfall definieren und Techniken vorstellen, um diese Herausforderungen von EdgeAI zu bewältigen. Wir beginnen mit der Vorstellung des Anwendungsfalls, anschließend beschreiben wir den Datensatz und das Modell. Danach schaffen wir Einblicke in zwei Strategien zur Modellkomprimierung – Pruning und Quantisierung – und vergleichen diese. Abschließend ziehen wir ein Fazit aus unseren Erkenntnissen und werfen einen Blick auf mögliche Entwicklungen und Herausforderungen in diesem Bereich.
Die Nicht-intrusive Lastüberwachung (NILM) ist eine Technologie, die es ermöglicht, den Energieverbrauch einzelner Geräte in einem Haushalt oder Unternehmen zu überwachen, indem die Gesamtstromlast an einem zentralen Verteilungspunkt analysiert wird.
Angenommen, Sie betreiben eine Produktionslinie, die mit einer Vielzahl von Motoren ausgestattet ist. Jeder dieser Motoren, ob es sich um den Antriebsmotor eines Fließbands, den Servomotor eines Roboters oder den Schrittmotor eines Positioniersystems handelt, hat seinen eigenen spezifischen “Energieverbrauchsfingerabdruck”, der mit Hilfe von NILM erkannt werden kann. Der Antriebsmotor könnte beispielsweise während der Hochlastzeiten einen Spitzenenergieverbrauch aufweisen, während der Servomotor einen variablen Energieverbrauch hat, der von der Komplexität der Roboterbewegungen abhängt.
Wenn eine Maschine, oder ein Gerät in einer Produktionsanlage, in Betrieb genommen wird, identifiziert das NILM-System das spezifische Energieverbrauchsmuster dieser Maschine aus dem Gesamtstromverbrauch und übermittelt diese Informationen an das Überwachungssystem der Firma. Basierend auf diesen Daten können beispielsweise detaillierte Berichte über den Stromverbrauch einzelner Anlagen erstellt werden. Dadurch können Entscheidungen getroffen werden, die den Stromverbrauch reduzieren und Kosten senken können.
Ein weiterer Anwendungsfall, der direkt auf die Industrie übertragen werden kann, ist Predictive Maintenance mit NILM. Predictive Maintenance, auch als “vorrauschauende Wartung” bekannt, bezeichnet den Prozess der frühzeitigen Wartung von Geräten, um einen unerwarteten Ausfall zu verhindern. Diese Wartung basiert im Falle von NILM auf Abweichungen im typischen Stromverbauchsmuster des jeweiligen Geräts. Durch die Implementierung von NILM könne Unternehmen frühzeitig Anomalien im Energieverbrauch erkennen und so präventive Maßnahmen ergreifen, um Ausfälle zu vermeiden und die Effizienz ihrer Produktionsanlagen zu maximieren. Dieser Ansatz ermöglicht es Unternehmen, ihre Wartungsstrategien zu optimieren und Stillstandszeiten zu minimieren, was letztendlich zu einer gesteigerten Produktivität und Kosteneffizienz führt.
In diesem Blogbeitrag wollen wir die Möglichkeiten von NILM on the Edge mittels des Tracebase Datensatzes demonstrieren.
Der Tracebase-Datensatz ist eine Sammlung von Stromverbrauchsspuren (eng. Trace) von elektrischen Geräten, die für die Forschung im Bereich der Energieanalyse verwendet werden können. Die Spuren wurden von einzelnen elektrischen Geräten mit einer durchschnittlichen Frequenz von einer Probe pro Sekunde gesammelt. Die Daten wurden in unterschiedlichen deutschen Haushalten in Darmstadt über mehrere Tage erhoben. Der Datensatz besteht aus 32 unterschiedlichen Geräte-Klassen, mit 122 verschiedenen Geräten und insgesamt über 1200 Stromverbrauchsspuren.
Wir haben uns für ein 1D-Convolutional Neural Network(1D-CNN) zur Identifikation der einzelnen Geräte entschieden. Die 1D-CNNs Layer wurden für ein-dimensionale Daten, wie beispielsweise Zeitreihen, entwickelt [3]. Das Modell hat fünf 1D-CNN Schichten, jeweils gefolgt von einer „Max-Pooling“ Schicht, um ein „Overfitting“ zu reduzieren. Die letzten beiden Schichten sind voll verbunden. Als Aktivierungsfunktion haben wir die ReLU-Funktion verwendet und nach der Ausgangsschicht wurde eine Softmax-Funktion verwendet. Das Modell wurde in PyTorch implementiert und trainiert.
Es müssen einige Metriken festgelegt werden, um die Auswirkung der später vorgestellten Methoden zur Modellkomprimierung bewerten zu können. Im Sinne von EdgeAI haben wir besonderen Wert auf die Modellgröße in Megabyte, die Inferenzgeschwindigkeit für einen Batch an Daten, den BCE-Loss und den F1-Score gelegt, jeweils berechnet auf das Test-Set. BCE-Loss und F1-Score sind Metriken, die die Performance eines Modelles im Sinne der Genauigkeit der Vorhersagen beschreiben. Der BCE-Loss wird während des Trainingsprozesses minimiert, das bedeutet wir streben einen möglichst niedrigen Wert an. Der F1-Score liegt zwischen 0 und 1, wobei 1 die bestmögliche Klassifikationsleistung anzeigt.
Das Basismodell nimmt 0.83 MB an Speicherplatz ein. Es benötigt 54.9 ms für die Verarbeitung eines Inputs. Das Modell weist einen BCE-Loss und F1-Score von 2.97 und 0.68 vor. Die Werte sind solide aber haben noch Raum zur Verbesserung.
In diesem Abschnitt des Blogberichts, wollen wir uns den oben gestellten Fragen zu Edge Computing widmen und zwei Techniken vorstellen, die angewandt werden können, um die Herausforderung der limitierten Ressourcen zu bewältigen.
Zwei der wichtigsten Methoden für die Modellkompression, die die Größe und die Komplexität der Modelle reduzieren können, ohne die Genauigkeit stark zu beeinträchtigen, sind Pruning und Quantisierung. Diese Methoden können einzeln oder in Kombination angewendet werden.
Im Folgenden werden diese Methoden vorstellen und ihre Auswirkungen auf das Modell testen und vergleichen.
Pruning, auf Deutsch „Beschneidung“ ist eine Technik, die unnötige oder unwichtige Gewichte aus einem Modell entfernt, indem sie die Gewichte mit einem Schwellenwert vergleicht oder die Auswirkungen der Gewichte auf die Modellleistung bewertet. Pruning kann die Anzahl der Parameter und notwendigen Rechenoperationen in einem Modell erheblich verringern, was zu einer schnelleren Inferenz und geringerer Modellgröße führen kann.
Pruning lässt sich in zwei Hauptarten unterteilen. Beim strukturierten Pruning werden in der Regel ganze Neuronen, Filter oder Schichten entfernt, was zu einem stark komprimierten Netzwerk und einer beschleunigten Inferenz führen kann, ohne die Genauigkeit zu beeinträchtigen. Außerdem führt diese Pruningart dazu, dass beim Entfernen eines Neurons alle zugehörigen Gewichte ebenfalls entfernt werden. Unstrukturiertes Pruning bezieht sich auf das Entfernen einzelner Gewichte, was zu einem unregelmäßigen Muster von Nullen im Netzwerk führen kann.

Angesichts unseres Anwendungsfalls im Bereich EdgeAI, in dem die Echtzeitanalyse von Daten von entscheidender Bedeutung ist, legen wir großen Wert auf die Inferenzgeschwindigkeit. Deshalb haben wir uns für ein strukturelles Pruning entschieden. In der Praxis findet diese Technik einen breiteren Anwendungsbereich als unstrukturiertes Pruning, da keine besondere Hardware, wie beispielsweise KI-Beschleuniger, benötigt werden.
Wir haben bereits die Rolle der Gewichte hervorgehoben, aber wie bestimmen wir die Relevanz der einzelnen Parameter oder sogar Filter? Im Folgenden werden wir diese Frage klären und ein paar gängige Pruning Kriterien erläutern.
Ein intuitiver Weg, um den Einfluss (Importance) eines Gewichtes zu bestimmen ist der „magnitude-based“ Ansatz. Dieser Ansatz verwendet mathematische Verfahren, um den Einfluss eines Gewichts auf das Gesamtresultat des Netzes einzuschätzen. Die Vorteile eines Prunings, basierend auf der Größe der Gewichte, sind die einfache Art der Implementation und der niedrige Rechenaufwand, da die Wichtigkeit jedes Gewichts mit der Größenordnung allein bestimmt werden kann. Der Absolutwert ist nicht die einzige Größenordnung, die verwendet werden kann. Ein weiteres Beispiel für eine Größenordnung wäre die L2-Norm.
Die Wichtigkeit eines Gewichts kann außerdem durch die Auswirkung, die ein Pruning jenes Gewichtes auf den Trainingsverlust (Trainingsloss) hat, bestimmt werden. Dieses Kriterium hat das Potenzial kleine Gewichte, die für die Modellgenauigkeit wichtig sind, zu erhalten. Jedoch ist diese Methode sehr rechenaufwendig und führt eine neue Form von Komplexität in den Pruningprozess ein.
Außerdem gibt es die Möglichkeit Gewichte zufällig aus dem Netzwerk zu entfernen. Dieser Ansatz wird als eine einfache und allgemeine Baseline betrachtet, die gut funktionieren und als Benchmark für komplexere Pruningmethoden verwendet werden kann.
Es bleibt noch die Überlegung offen, ob wir das gewählte Kriterium auf das ganze Modell, also global, oder pro Schicht, d.h. lokal, anwenden. Hier spricht man von globalen und lokalen Pruning.
Globales Pruning zeigt in der Regel bessere Resultate als lokales Pruning. Jedoch, ist lokales Pruning leichter zu implementieren, deshalb empfehlen wir damit zu beginnen. Wir haben beide Methoden getestet und stellen unsere Resultate im nächsten Abschnitt vor.
Für die Implementation des strukturierten Prunings und unserem Benchmarking haben wir Torch-Pruning (TP) verwendet.
TP ist ein Open-Source Toolkit, das ermöglicht, strukturierendes Pruning für unterschiedliche neuronale Netzwerke, wie z.B. CNNs oder Large Language Models, zu betreiben. Es basiert auf dem Algorithmus „DepGraph“. Dieser Ansatz ist vergleichbar mit der Erstellung einer Karte, die zeigt, wie verschiedene Teile des Netzwerks voneinander abhängen. Dadurch wird es möglich, Parameter zu gruppieren, die eng miteinander verbunden sind, was es einfacher macht zu entscheiden, welche Teile des Netzwerks entfernt werden können, ohne einen signifikanten Leistungsverlust zu verursachen. [4]
Das Toolkit konnte direkt in das Projekt integriert werden. Es ist zu beachten, dass Schichten, die nicht geprunt werden sollen, wie z.B. die Ausgangsschicht, manuell festgelegt werden müssen.
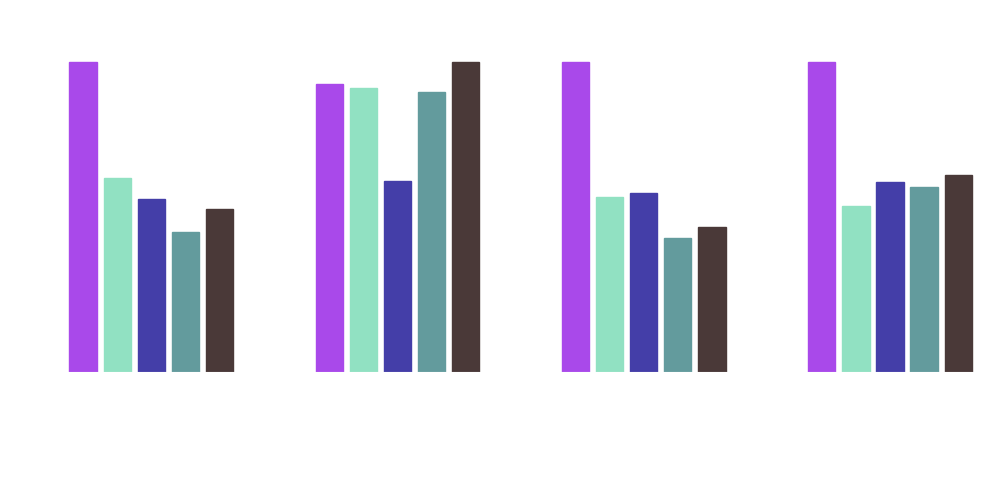
Pv = Pruningverhältnis, l. = lokal, g. = global
Wir haben verschiedene Pruning-Methoden auf unser neuronales Netzwerk angewendet. Die besten Resultate haben wir mit Magnitude Pruning erzielen können. Hier haben wir Gewichte basierend auf ihrer Größe (Magnitude) entfernt, gemessen durch die L1- und L2-Norm. Die L1- und L2-Norm sind gängige mathematische Normen, die in KI verwendet werden. Wie haben alle Pruningkonfigurationen sowohl lokal (innerhalb einzelner Schichten) als auch global (über das gesamte Netzwerk) durchgeführt.
Unsere Ergebnisse waren vielversprechend, bei einem lokalen Pruning konnten wir bis zu 25% der Parameter mit der L1-Norm und bis zu 50% der Parameter mit der L2-Norm entfernen, ohne dass die Leistung erheblich beeinträchtigt wurde. Bei globalem Pruning konnten wir bis zu 20% der Gewichte mit beiden Normen entfernen, bevor die Leistung deutlich abnahm. Wir konnten feststellen, dass das Pruning tatsächlich zu einer Verbesserung der Leistung, wie beispielsweise bei dem globalen Magnitude Pruning mit L2-Norm, führen kann, was darauf hindeutet, dass unser Model möglicherweise zu komplex ist und durch das Pruning eine bessere Generalisierung ermöglicht wird.
Insgesamt konnten wir die Größe unseres Modells um bis zu 57% reduzieren und die Inferenzgeschwindigkeit um bis zu 46% verbessern, ohne die Genauigkeit des Modells erheblich zu beeinträchtigen.
Durch Quantisierung verringert man die Bitbreite der Gewichte und Aktivierungen in einem Modell, indem die Dezimalwerte in ganzzahlige Werte umgewandelt werden. Quantisierung kann den Speicherbedarf und die Rechenzeit in einem Modell verringern, indem Datentypen mit geringerer Präzision, wie z.B. INT8 anstelle von FP32, verwendet werden. Das bedeutet, dass anstelle von 32 Bit lediglich 8 Bit für die Darstellung der Gewichte im Speicher verwendet werden.
PyTorch bietet einige Möglichkeiten, um eine Quantisierung eines neuralen Netzes durchzuführen. Um eine Quantisierung durchführen zu können müssen Quantisierungsparameter berechnet werden. Das erfolgt in PyTorch automatisch und dient dazu die Gewichte richtig zu skalieren. Die Berechnung kann entweder statisch oder dynamisch erfolgen. Bei einer statischen Quantisierung werden die benötigten Quantisierungsparameter zur Skalierung der Werte durch Beispielsdaten vorberechnet, gegensätzlich dazu wird in der dynamischen Quantisierung die Parameter während des Pruningprozesses berechnet und angepasst. Außerdem ist es wichtig, ob das Berechnen der Parameter mit oder ohne Neutrainieren passieren soll. Hier wird von „Post-Training-Quantization“ (PTQ) oder „Quantization-Aware-Training“ (QAT) gesprochen.
In unserem Projekt haben wir uns für eine statische PTQ entschieden. PTQ ist ressourcensparender als QAT und in PyTorch wird keine dynamische Quantisierung der “Convolution Layer” unterstützt. Das Ziel ist es die Parameter von FP32 auf INT8 zu quantisieren. Es ist wichtig zu berücksichtigen, dass der Quantisierungsprozess speziell auf die zukünftige Hardware abgestimmt werden muss, auf der das Modell ausgeführt wird.
Durch Quantisierung haben wir eine über 70%ige Reduzierung der Modellgröße und eine über 50%ige Verbesserung in der Inferenzgeschwindigkeit beobachten können. Diese Verbesserung erhöhen den Loss deutlich, aber wir haben nur eine kleine Minderung des F1-Scores von 7%. Eine Zunahme des Loss-Wertes signalisiert, dass unser Modell größere Abweichungen von den tatsächlichen Werten aufweist. Trotz dieser Zunahme zeigt die nur geringfügige Reduzierung des F1-Scores, dass unser Modell in Bezug auf die Genauigkeit immer noch zufriedenstellende Ergebnisse liefert.
Quantisierung stellt sich als starkes und leicht verwendbares Tool heraus, um die Modellgröße und Inferenzgeschwindigkeit zu verbessern. Aber es geht noch kleiner und schneller. Die beiden Techniken, Pruning und Quantisierung, grenzen nicht gegeneinander aus, sondern können kombiniert werden, um das Modell weiter zu verkleinern. Wir haben das bereits zu 25% geprunte „Magnitude L2 global“ Modell quantisiert und die Auswirkungen getestet.
Als Abschluss möchten wir alle getesteten Konfigurationen zusammen präsentieren. Die Grafik stellt sehr gut, die Vorteile, die durch Pruning und Quantisierung realisiert werden können, da.
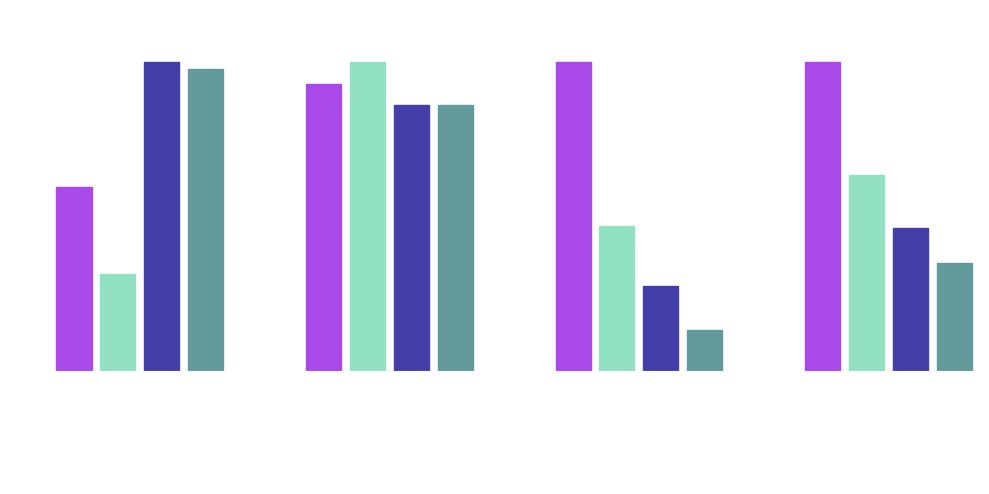
Vergleich der Ergebnisse
Die höchste Kompressionsrate und schnellste Inferenzgeschwindigkeit wurden mit einer Kombination aus diesen beiden Techniken erzielt. Allerdings nimmt auch die Modelleistung am meisten ab. Im Vergleich zu dem Basismodell wurde die Modellgröße um 87% reduziert und das Modell ist zu 65% schneller.
In diesem Blogbeitrag haben wir EdgeAI, die Vorteile und Herausforderungen, sowie einen potenziellen Anwendungsfall vorgestellt. Außerdem haben wir zwei Techniken – Pruning und Quantisierung – getestet. Diese Methoden der Modellkomprimierung sind ein guter Startpunkt, um die Herausforderung des beschränkten Speicherplatzes und der limitierten Rechenleistung zu bewältigen.
Mit Pruning konnten wir, im Falle des “Magnitude-based L2 Global” pruning, die Modellgröße um 57% reduzieren und die Inferenzgeschwindigkeit konnte zu 46% verbessert werden, außerdem wird der Regularisierungseffekt deutlich. Durch die Technik wurde klar, dass wir eine bestimmte Anzahl an Parameter aus unserem Modell entfernen können, ohne große Verluste in der Modellperformance zu erleiden.
Quantisierung stellt sich als effektive, leicht anwendbare Technik zur Modellkomprimierung heraus. Mit dieser Methode konnten wir eine 70% Reduzierung der Modellgröße und eine 50% verbesserte Inferenzgeschwindigkeit erzielen.
Die höchste Kompressionsrate und niedrigste Inferenzgeschwindigkeit konnten mit einer Kombination aus den zwei Techniken erzielt werden, jedoch sinkt auch der F1-Score am meisten und der BCE-Loss steigt. Die Modellgröße wurde bis zu 87%verkleinert im Vergleich zu dem Basismodell. Die Inferenzgeschwindigkeit hat sich zu 65 % verbessert. In Angesichts der Verbesserungen ist eine Reduzierung des F1-Scores von 7 % für diesen Use Case “akzeptabel”.
Die Vorteile dieser Techniken sind deutlich und unserer Meinung nach ein wichtiger Schritt, um eine Herausforderung von EdgeAI zu bewältigen. Um EdgeAI in Zukunft weiter voranzubringen, könnten weitere Schwierigkeiten wie der Energieverbrauch der Edge-Geräte oder Datenschutz und Sicherheit genauer betrachtet werden. Außerdem bleibt die Frage offen, wie die neuen AI-Modelle auf das Endgerät deployt und gepflegt werden können, was in eine zukünftigen Blogbeitrag adressiert werden soll. Wir wollen die Vorteile von Kubernetes und Edge AI verbinden und einen potenziellen Ausblick auf MLOps at the Edge bieten.
Weitere Informationen:
[1] https://www.fortunebusinessinsights.com/edge-ai-market-107023
[2] https://www.areinhardt.de/publications/2012/Reinhardt_SustainIt_2012.pdf
[3] https://www.mdpi.com/1996-1073/16/5/2388
[4] https://github.com/VainF/Torch-Pruning/tree/master
[5] https://www.sciencedirect.com/science/article/pii/S2667345223000196
